Thinking in Transformers
Chapter 0: The Design Space of Language Models
A working model for understanding LLMs as compressed, lossy, differentiable databases of language.
A large language model can write a workable web crawler, summarize a legal brief, explain backpropagation, and then stumble on something that looks embarrassingly simple, like reversing a short string or counting letters in a word. If your mental model is just "it predicts the next token," all of that is technically consistent and almost none of it is explained.
That sentence, "predicts the next token," names the training objective. It does not tell you what kind of object the model becomes after training. And if you carry the wrong object in your head, the rest of the field stays blurry. Scaling laws look like a curiosity. Attention variants look like cosmetic tweaks. Inference engineering looks like implementation trivia. Alignment looks like a thin layer of polish on top of intelligence. None of those pictures are quite right.
The model I want to put in your head instead is this: An LLM is a compressed, lossy, differentiable database of language.
That phrase is useful because it makes the entire design space legible.
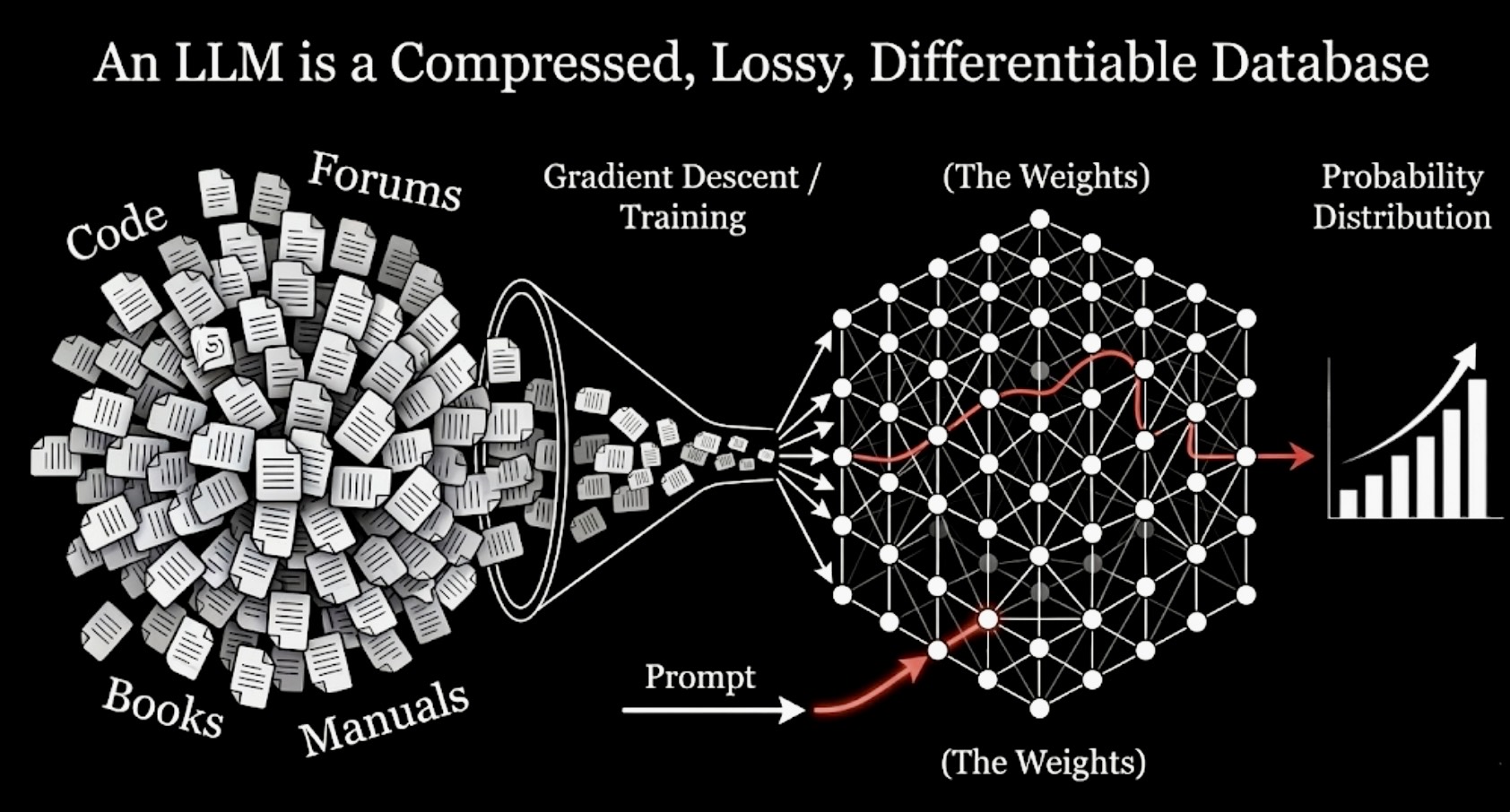
A useful mental model for the rest of this chapter: pretraining compresses a huge corpus into weights, and inference queries that learned store through context.
Compressed, because the model takes an absurd amount of text and distills it into a finite set of parameters. Terabytes of documents, books, code, conversations, manuals, comments, proofs, and forum arguments are pushed through gradient descent until what remains is a dense numerical object that fits on a cluster and, eventually, on a few serving machines.
Lossy, because most of that original material cannot survive intact. The model cannot keep every sentence, every table, every exact phrasing, every rare edge case. It has to preserve patterns and discard details. Some of what it discards is unimportant noise. Some of it turns out to matter a lot. A surprising amount of modern model behavior, both impressive and frustrating, is downstream of what got compressed well and what did not.
Differentiable, because both storage and retrieval happen through smooth functions learned end to end. You do not query the system with a symbolic key and get back a clean row from a table. You give it context, it maps that context through layers of matrix multiplications and nonlinearities, and it returns a probability distribution over continuations. Everything is soft. Everything is approximate. Everything is optimized by gradients.
Database, because the weights really do store a vast amount of structured information, and the forward pass really is a retrieval process of a kind. The analogy breaks if you push it too far. An LLM does not support exact lookup. It has no reliable notion of primary key. It cannot guarantee faithful recall of a fact just because that fact appeared in the training data. But as a working model, "database" is far more useful than "spicy autocomplete." It emphasizes storage, compression, retrieval, and failure modes. Those are the concepts that actually matter when you try to understand why these systems work and where they break.
That framing gives us a way to think about the whole pipeline. Tokenization becomes the first compression scheme. Architecture becomes a decision about what kinds of patterns can be stored and retrieved. Pretraining becomes the process that writes the database. Post training becomes the process that changes what the system prefers to surface. Inference becomes the problem of querying this learned store efficiently under hard latency and memory constraints.
This chapter is about installing that lens. Once it clicks, later chapters stop feeling like disconnected topics. Tokenization, embeddings, attention, scaling, alignment, serving, multimodality: all of them become different answers to the same underlying question. What are we storing, what are we losing, and how are we searching for it?
What an LLM actually is
Strip away the anthropomorphism and an LLM is a function. It takes a sequence of token IDs and returns a vector of scores over the vocabulary for the next token. After a softmax, those scores become probabilities. Sample from that distribution, append the sampled token, run the function again, and you get generation.
That bare description is accurate, but still too thin to be useful. The important part is what sits inside the function.
A trained model is parameterized by billions of weights. Those weights are the only persistent store the model has. There is no hidden notebook of facts. No internal document index. No symbolic memory that survives across conversations. When you start a fresh session, the model has exactly two sources of information: the weights, which encode what was learned during training, and the current context window, which contains the tokens you have given it so far. There is no third source.
That matters because it tells you how to reason about both competence and failure. If the model knows that Paris is the capital of France, that knowledge is not stored as a neat symbolic record. It exists as a distributed configuration of weights such that prompts like "The capital of France is" push the network toward an internal state whose output distribution peaks around "Paris." If the model can write plausible code in a framework it has seen often, that ability is not coming from a hard-coded API manual inside the network. It is coming from patterns in weight space that let certain textual contexts activate the right continuations.
Knowledge, in a language model, is geometric. Retrieval is numerical. The model does not go and fetch a sentence. It moves through a learned space in which some continuations have become high-probability responses to some contexts. This is why paraphrase works. It is why nearby prompts can produce similar answers even when the exact phrasing never appeared in training. It is also why the same model can sound certain while being wrong. Approximate retrieval is powerful. It is not faithful by default.
This also helps explain a pattern that often confuses new readers. LLMs are remarkably good at tasks that look broad and fuzzy and sometimes surprisingly brittle on tasks that look sharp and narrow. The model may produce coherent code because the statistical structure of code is rich, repetitive, and heavily represented in training. It may still fail at a short character manipulation task because the computation required is not naturally supported by the tokenization, the architecture, or the learned heuristics that usually carry language generation. The failure is not mysterious. It is a clue about what the model compressed well and what it did not.
If you keep that picture in mind, many later phenomena become less magical. In-context learning becomes less like on-the-fly reasoning from nowhere and more like fast adaptation through pattern activation in a system that already stores immense statistical structure. Hallucination stops looking like a random bug and starts looking like approximate retrieval under weak evidence. Scaling laws stop looking mystical and start looking like statements about what kinds of structure can be compressed as you increase model size, data, and compute.
The pipeline is a cascade of commitments
There is a strong temptation to think of the LLM pipeline as a sequence of implementation steps. Gather data, tokenize it, train a model, fine-tune it, serve it. That view is not wrong, but it misses the more important point. Each stage makes commitments that constrain every stage after it. Once a choice is made upstream, many downstream possibilities simply disappear.
A more useful way to think about the pipeline is as a cascade of irreversible decisions.
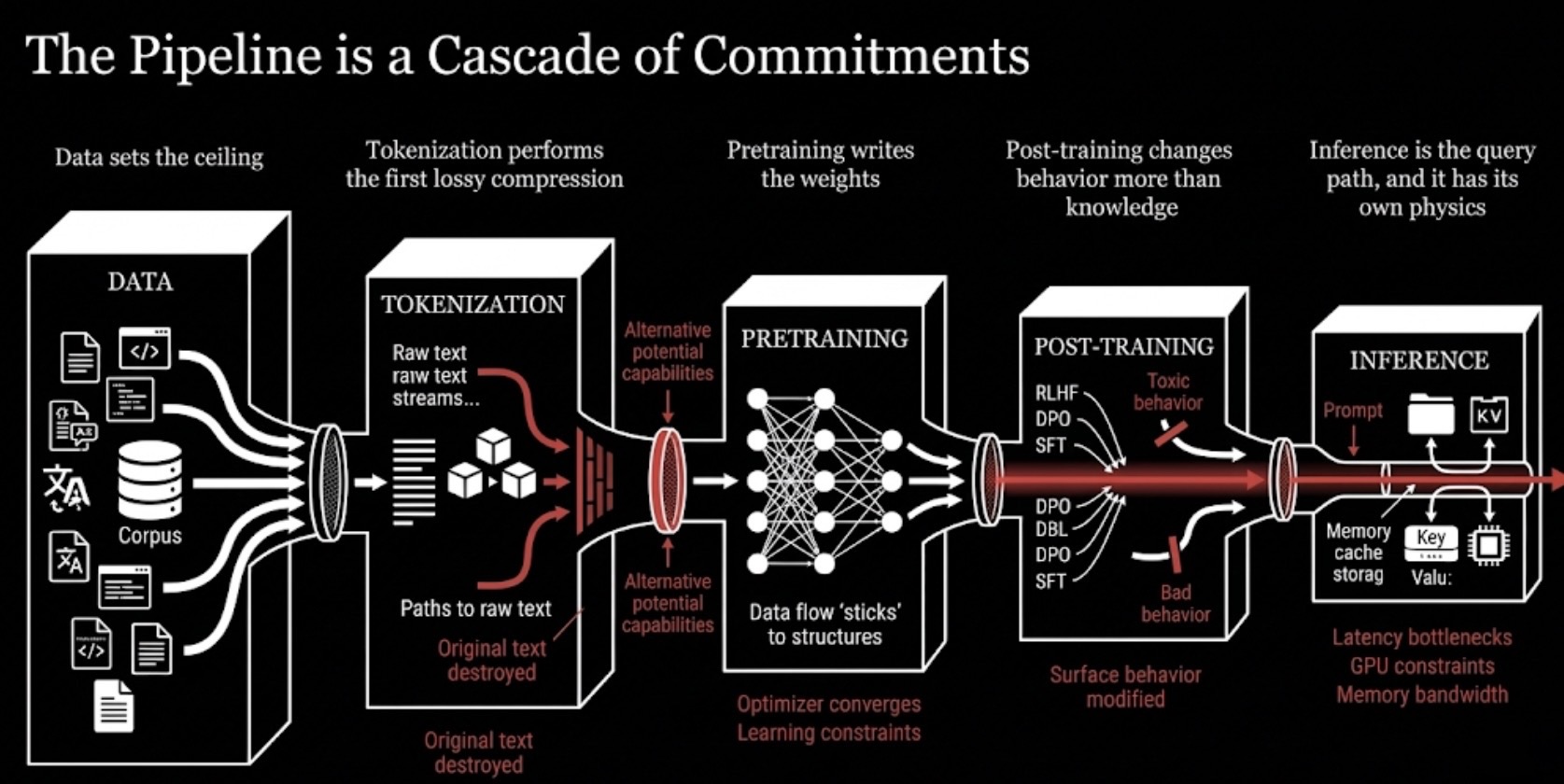
The pipeline is not just a workflow. Each stage compresses options for the stages that follow and leaves behind different kinds of constraints.
1. Data sets the ceiling
The model cannot learn what is not present in the corpus, and it will learn unevenly from what is. A corpus dominated by English web text produces a model that speaks English fluently and treats many other languages as second-class residents. A corpus rich in casual prose and poor in formal mathematics produces a model that can talk about proofs more easily than it can carry one through with precision. A corpus full of repeated boilerplate encourages memorization of common forms. A corpus with contradictory claims encourages the model to internalize ambiguity.
This point sounds obvious until you see how often people forget it. When a model fails on some domain-specific task, the instinct is often to blame the visible layer nearest the surface: bad alignment, bad prompting, bad decoding. Sometimes the real explanation is much simpler. The model never saw enough high-quality signal in that domain to compress it well in the first place.
Data quality matters just as much as data quantity. Duplicates distort the effective distribution. Low-quality text teaches bad habits at scale. Synthetic or templated data can create uncanny confidence without deep competence. The dataset does not merely provide examples. It defines the world the model gets to compress.
2. Tokenization performs the first lossy compression
Before the model learns anything, someone has decided how raw text will be chopped into tokens. That choice looks mundane until you trace its consequences.
A tokenizer determines vocabulary size, average sequence length, multilingual coverage, how code is segmented, how numbers are split, and how expensive every later step becomes. Poor tokenization can make one language far more expensive than another in context length. It can turn simple arithmetic into a mess by splitting digits in unhelpful ways. It can fragment rare words into long byte-level chains. It can impose a hidden tax on every attention layer that follows.
This is the first place where information is destroyed. Once the text has been discretized, the model never gets to see the raw stream again. If an important structure is broken here, no amount of optimization later can fully recover it. Chapter 1 will spend a lot of time on this because tokenization quietly shapes far more behavior than most people realize.
3. Pretraining writes the weights
Architecture determines the function class. Training determines which function within that class you actually get.
Those are different questions. A transformer with enough width and depth can, in principle, represent an enormous range of behaviors. In practice, the optimizer only discovers some of them. Learning rate, batch size, curriculum, data mixture, sequence length, initialization, normalization, precision format, training duration, and distributed training strategy all shape where the run converges.
This is one reason the phrase "same architecture" is less informative than it sounds. A model trained twice as long on a cleaner dataset with a different tokenizer and a better learning-rate schedule may be qualitatively different even if the block diagram is unchanged. The architecture tells you what the model could become. The training regime tells you what it became.
Pretraining is where the database is written. It is not writing symbolic entries one by one. It is repeatedly updating weights so that useful regularities in text are compressed into a predictive system. Some patterns get stored in ways that generalize broadly. Some get stored only weakly. Some never get stored at all. Every capability you care about later depends on what survived this compression.
4. Post training changes behavior more than it changes knowledge
After pretraining, the model is usually fluent, broad, and badly behaved. It may answer helpfully on some prompts and catastrophically on others. It may be toxic, evasive, verbose, sycophantic, or simply hard to steer. Post training exists to shape behavior.
Supervised fine-tuning gives the model examples of preferred responses. Preference optimization methods, whether PPO-based RLHF, DPO, or close relatives, teach the model which outputs humans or judges tend to prefer. This can dramatically improve usefulness. It can also distort style, confidence, refusal behavior, and diversity.
The key point is that post training mostly changes what the model chooses to surface and how it presents it. It is much less effective at writing deep new capabilities into the network from scratch. A pretrained model that never internalized good mathematical structure will not become a theorem prover because you fine-tune it on a small alignment dataset. What post training often does, very effectively, is take latent capabilities that are already there and make them easier or harder to elicit.
This is why aligned and base models can feel so different in conversation while still sharing the same underlying substrate. One has been taught a new response policy over roughly the same internal store.
5. Inference is the query path, and it has its own physics
Once the model is trained, the problem changes completely. Training is about writing the database. Inference is about querying it quickly enough and cheaply enough to be useful.
At this stage the clean theoretical view runs into hardware reality. Tokens are generated one at a time. Each new token requires a forward pass. Attention wants access to prior context. The key-value cache grows with sequence length. Memory bandwidth, cache layout, batching strategy, quantization, and scheduling begin to matter as much as the elegant math in the paper.
This is why serving large models feels like a separate discipline. You can understand the transformer perfectly and still be surprised when the bottleneck in production is moving tensors around, not multiplying them. A lot of modern efficiency work is best understood as a response to this physical fact. The model may be mathematically defined by floating-point operations, but it lives or dies on real hardware with finite memory and ugly latency constraints.
Seen this way, the pipeline is not a checklist. It is a chain of bottlenecks. If a model hallucinates, the cause might be a post-training issue. Or it might be ambiguous data upstream. Or weak tokenization of numbers. Or a context that is too long and forces brittle retrieval. The essential analytical skill in this field is learning to trace a behavior back through the cascade and ask where the real constraint entered.
The six tensions that organize the field
Every important design choice in modern language models sits on one or more recurring tradeoffs. These are the axes I reach for first when I read a new paper. If you can place a method on these tensions, you usually understand it well enough to predict what it buys and what it costs.
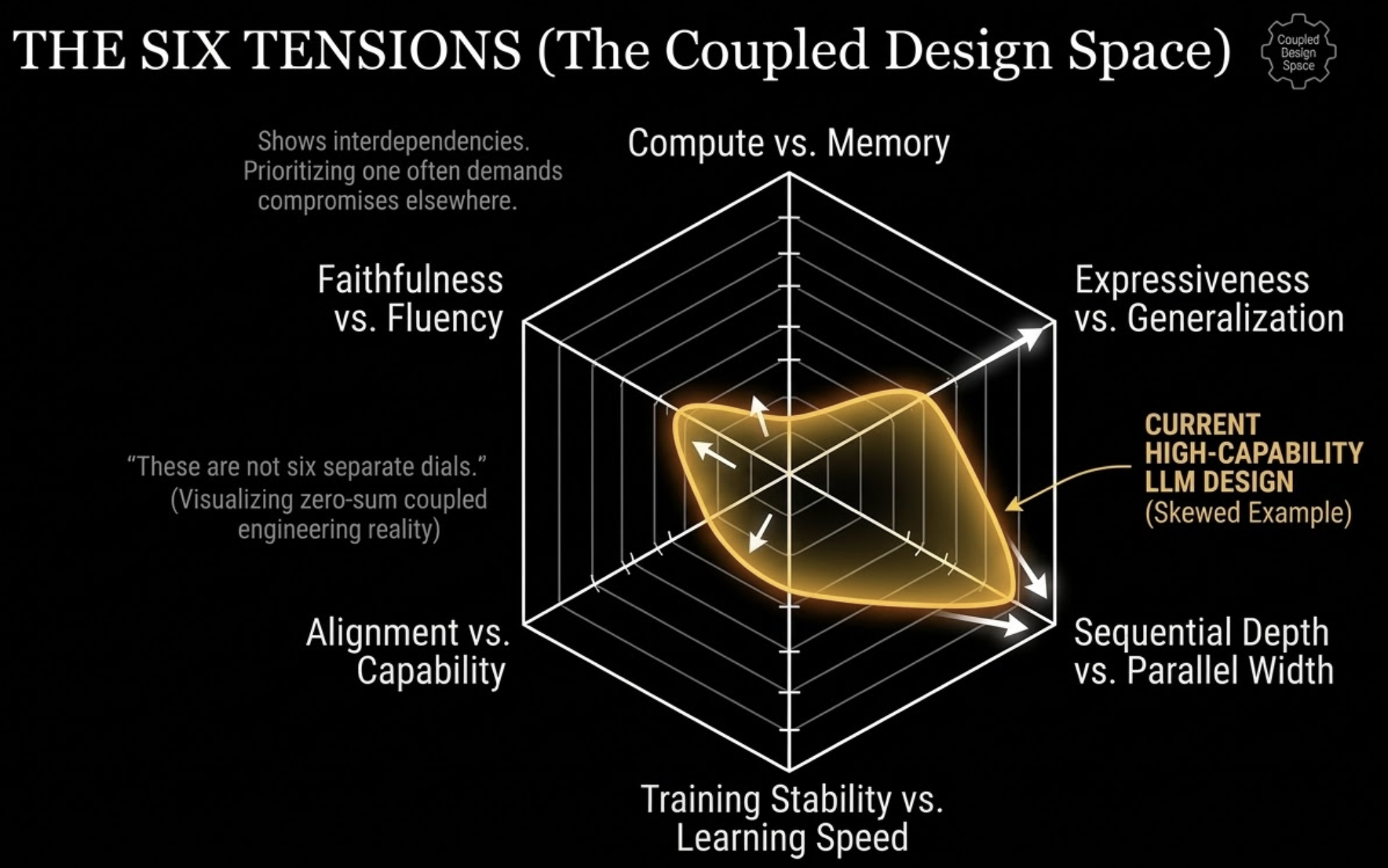
These tradeoffs are coupled rather than independent. Pushing hard on one axis usually creates pressure somewhere else in the system.
Compute vs. memory
On modern accelerators, doing math is often cheaper than moving data. This is the least intuitive and most practically important fact in the whole stack.
FlashAttention is the canonical example. It computes the same attention function as the naive implementation. The improvement is not that the math changed. The improvement is that the computation is reorganized so far less intermediate data is materialized and moved through high-bandwidth memory. Same function, very different runtime profile.
The same logic shows up again at inference. The key-value cache is useful because it saves recomputation, but it is also a memory burden that grows with context length. Many "efficiency" innovations are really memory innovations in disguise.
Expressiveness vs. generalization
More parameters let the model represent more structure. They also make memorization easier and optimization trickier. Bigger models often generalize better, but only when supported by enough data and the right training regime. Capacity is not free.
Mixture of Experts (MoE) makes this tradeoff explicit. You can increase total parameter count dramatically while only activating a subset per token. That buys expressiveness without paying the full dense compute cost each time. It also introduces routing problems, load-balancing issues, and new ways for specialization to go wrong.
The deeper principle is simple: capacity changes what can be stored. It also changes what is likely to be stored.
Training stability vs. learning speed
Fast learning and stable learning are rarely the same thing.
Aggressive learning rates, large batches, long context lengths, and thin numerical margins can make training efficient until the run explodes. Conservative settings are slower but forgiving. Much of modern transformer design is a negotiation with this fact.
Pre-norm architectures won in practice for a reason. They are easier to scale reliably. Warmup schedules exist for a reason. Mixed-precision formats require care for a reason. When training runs cost real money, stable optimization is not a luxury. It is a design constraint.
Sequential depth vs. parallel width
Deeper models compose transformations across many layers. Wider models process more features at once. More importantly, sequence models themselves must choose where to place sequential structure.
Recurrent networks process tokens in order and carry state forward step by step. Transformers process tokens in parallel within a layer and recover order through explicit positional mechanisms. That exchange was decisive. We gave up an innate sequential inductive bias and gained massive parallelism.
The costs are still with us. Attention scales badly with long context. Positional encoding becomes a first-class architectural concern. Length generalization becomes something you have to engineer, not something the architecture gives you naturally.
Alignment vs. capability
A raw pretrained model and a user-facing assistant are not the same thing. Post training makes models more useful, safer, and easier to control. It can also narrow behavior in undesirable ways.
The alignment tax is real. It may show up as increased refusal, reduced diversity, greater hedging, or sycophancy. Sometimes those tradeoffs are exactly what you want. Sometimes they suppress useful behavior that happens to be adjacent to risky behavior in the reward signal.
The right question is never whether alignment has a cost. It does. The question is whether the cost is targeted and acceptable for the application.
Faithfulness vs. fluency
Language models are optimized to continue text plausibly, not to guarantee truth. Those are related goals, not identical ones.
A model can sound beautifully coherent while drifting away from reality. It can also produce a hesitant, less polished answer that is closer to the truth. Decoding choices expose this tension directly. Greedy decoding is conservative but dull. Higher temperature increases diversity and often creativity, but it also lets the model wander into low-confidence regions where confident nonsense becomes more likely.
This tension does not disappear with better models. It just shifts. Stronger models can be both more fluent and more faithful, but the gap never closes by default.
These are not six separate dials
I have named six tensions, but the field is not organized into neat independent sliders. Most real choices pull on several of them at once.
Take vocabulary size. A larger vocabulary can shorten sequences, which reduces attention cost and key-value cache growth. That sounds good on compute and memory. But it also means a bigger embedding matrix, more rare tokens with fewer training examples, and potentially weaker generalization for infrequent pieces. Change the tokenizer and you have changed optimization dynamics, memory use, multilingual behavior, code handling, and even aspects of alignment, because the granularity of generation affects what the model can do cleanly at all.
Or take grouped-query attention. It reduces memory pressure at inference by sharing keys and values across groups of heads. That is a compute-and-memory play. It may also slightly reduce expressiveness relative to full multi-head attention. Whether that cost matters depends on scale, task, and serving constraints. The technique only makes sense when you see it as a point in a coupled design space, not as a free improvement.
This is the habit I want you to build. When you read a paper, do not ask only what new mechanism it introduces. Ask which tension it is trying to relieve, which new pressure it creates elsewhere, and whether the exchange rate seems worth it.
That is how the field starts to look coherent.
Three architecture families, one central question
The major transformer families differ mainly in how they allow tokens to see context.

The cleanest way to compare the major families is by attention pattern: bidirectional encoding, causal decoding, or a hybrid encoder-decoder split.
Encoder only
Encoder-only models, like BERT, let every token attend bidirectionally to every other token in the input. This is excellent for building rich contextual representations. It is much less natural for autoregressive generation, because the model is not organized around predicting the future from the past.
BERT mattered because it proved that large-scale pretraining could dramatically improve downstream language understanding. It changed the field. It was not the architecture that ended up dominating generative deployment.
Decoder only
Decoder-only models, like GPT-style systems, enforce a causal mask. Each token sees only the tokens before it. That structure makes generation natural. Predict a token, append it, repeat.
This architecture won because of simplicity and scale. One stack, one objective, one clean autoregressive loop. It turns out that a very large decoder-only model can do an enormous range of tasks by generating the right continuation, including tasks that older NLP pipelines would have treated as classification, extraction, or structured prediction.
The cost is structural. The model never gets true bidirectional access to future context inside the same sequence position. It has to approximate many forms of understanding through a fundamentally causal setup.
Encoder-decoder
Encoder-decoder models, like T5, combine both patterns. The encoder builds a bidirectional representation of the input. The decoder generates autoregressively while attending to that encoded representation.
This is, in many ways, the most architecturally flexible family. It is especially natural for tasks that look like transforming one sequence into another. Translation, summarization, and many supervised text-to-text problems fit it beautifully.
Why did it not dominate at the very largest scales? Mostly because simplicity has a compounding advantage. Decoder-only systems are easier to scale, easier to unify under a single objective, and easier to deploy across a wide range of tasks with a single interface. That was enough to make them the default choice, at least for now.
I say "for now" deliberately. Decoder-only dominance should not be mistaken for theoretical finality. It is the winner of the current engineering equilibrium, not necessarily the last word on sequence modeling.
A compact glossary for the rest of the series
- Token: a discrete unit from the model's vocabulary. It may be a word, subword, byte sequence, punctuation mark, or fragment.
- Embedding: a learned vector representation of a token. The embedding matrix maps token IDs into continuous space.
- Logit: the raw score the model assigns to each possible next token before softmax.
- Softmax: the function that converts logits into a probability distribution over tokens.
- Cross entropy: the standard training loss for next-token prediction. It measures how much probability mass the model assigned to the correct next token.
- Perplexity: a transformed version of cross entropy that is often easier to interpret. Lower perplexity means better predictive performance.
- Context window: the number of tokens the model can condition on at once.
- Parameter count: the number of trainable weights in the model. It is a rough measure of capacity, not a complete description of ability.
These definitions are simple on purpose. Later chapters will deepen them where needed, but they will keep the same core meaning throughout.
The lens you should leave with
If this chapter has worked, you should now see a language model less as a chatbot and more as a compressed system for storing and retrieving statistical structure from language. You should see the pipeline that builds it as a series of irreversible commitments. And you should have six tensions in mind that make new ideas easier to place.
That is the real goal of Chapter 0. Not vocabulary. Not hype. A lens.
With that lens, the rest of the series becomes easier to navigate. Tokenization is no longer a preprocessing detail. It is the first compression scheme and the first place where structure is lost. Positional encoding is no longer a bolt-on trick. It is how the architecture breaks a symmetry that would otherwise make order invisible. Attention is no longer just a famous block in a diagram. It is a differentiable retrieval mechanism with very specific computational costs. Post training becomes steering. Inference becomes systems engineering under memory constraints. Architecture variants become explicit bets on which tension matters most.
By the time we are done, I want you to be able to pick up a new paper, look at the architecture diagram, and immediately ask the right questions. What is this method trying to compress better? What failure mode is it trying to repair? Which tension is it moving on? What did it gain, and what did it have to pay?
That is the habit that turns facts into intuition.
The next chapter starts where every language model starts: with tokenization. Before the model learns syntax, facts, code, or reasoning, someone has to decide what counts as a unit. That decision looks innocent. It is not. It determines sequence length, memory cost, multilingual coverage, and a surprising number of downstream failure modes. It is the first bottleneck in the entire stack, which is exactly why it is the right place to begin.